参考资料:
写在开头:本文为学习后的总结,可能有不到位的地方,错误的地方,欢迎各位指正。
目录
Redis通过将热点数据存储到内存中实现了高效的数据读取,但是内存如果使用不当也是会造成一些问题的。
- Redis中有很多无效的缓存,这些缓存数据会降低数据IO的性能,因为不同的数据类型时间复杂度算法不同,数据越多可能会造成性能下降
- 随着系统的运行,redis的数据越来越多,会导致物理内存不足。通过使用虚拟内存(VM),将很少访问的数据交换到磁盘上,腾出内存空间的方法来解决物理内存不足的情况。虽然能够解决物理内存不足导致的问题,但是由于这部分数据是存储在磁盘上,如果在高并发场景中,频繁访问虚拟内存空间会严重降低系统性能。
因此,Redis为了更好的管理内存,提供了一些管理方案,包括过期策略与内存淘汰。
过期策略是指对每个存储到redis中的key设置过期时间。Redis提供了 EXPIRE 与 EXPIREAT 来为 key 设置过期时间。
redis> SET mykey "Hello" "OK" redis> EXPIRE mykey 10 (integer) 1 redis> TTL mykey (integer) 10 redis> SET mykey "Hello World" "OK" redis> TTL mykey (integer) -1 redis>当到达过期时间后,就需要将这个key删除掉(准确来说,是该key会变为不可使用,而后再利用专门的过期策略对其进行删除)。Redis中提供了两种过期删除策略:惰性删除和定期删除。
1、定期删除
定期删除类似一个守护线程,每间隔一段时间就执行一次(默认100ms一次,可以通过修改配置文件redis.conf 的 hz 选项来调整这个次数),将过期的Key进行删除,具体过程如下:
- 从过期字典中随机选出20个key;
- 删除这20个key中已经过期的key;
- 如果过期的key的比例超过了1/4,那就重复从步骤1开始执行;
之所以不一次性将所有过期的key都删除,是从性能角度做出的考量,当过期key特别多时,每次扫描全部的过期key,都会给CPU带来较大负担。既然无法一下子全部删除,那么我就进行多次(指每100ms执行一次,提高删除的频次)、部分的删除(只每次只抽取部分进行删除),以此来达到效果。
当然,这样随机的抽取过期key进行删除明显会遗漏很多过期key,这就要用到惰性删除。
2、惰性删除
惰性删除即当查询某个Key时,判断该key是否已过期,如果已过期则从缓存中删除,同时返回空。
这一块的思路其实挺类似mysql的内存数据写回策略Merge buffer,只不过一个是写回磁盘一个是从内存删除。有兴趣的朋友可以看看我之前的文章《mysql中的Innodb_buffer_pool》

再回头看看过期策略,无论是定期删除还是惰性删除,都是一种不完全精确的删除策略,始终还是会存在已经过期的key无法被删除的场景。而且这两种过期策略都是只针对设置了过期时间的key,不适用于没有设置过期时间的key的淘汰,所以,Redis还提供了内存淘汰策略,用来筛选淘汰指定的key。
在配置文件redis.conf 中,可以通过参数 maxmemory <bytes> 来设定最大内存,当数据内存达到 maxmemory 时,便会触发redis的内存淘汰策略(我们一般会将该参数设置为物理内存的四分之三)。
当 Redis 的内存超过最大允许的内存之后,Redis 会触发内存淘汰策略。(过期策略是指正常情况下清除过期键,内存淘汰是指内存超过最大值时的保护策略)。内存淘汰策略可以通过maxmemory-policy进行配置,目前Redis提供了以下几种(2个LFU的策略是4.0后出现的):
- volatile-lru,针对设置了过期时间的key,使用lru算法进行淘汰。
- allkeys-lru,针对所有key使用lru算法进行淘汰。
- volatile-lfu,针对设置了过期时间的key,使用lfu算法进行淘汰。
- allkeys-lfu,针对所有key使用lfu算法进行淘汰。
- volatile-random,从所有设置了过期时间的key中使用随机淘汰的方式进行淘汰。
- allkeys-random,针对所有的key使用随机淘汰机制进行淘汰。
- volatile-ttl,针对设置了过期时间的key,越早过期的越先被淘汰。
- noeviction,不会淘汰任何数据,当使用的内存空间超过 maxmemory 值时,再有写请求来时返回错误。
除了比较特殊的noeviction与volatile-ttl,其余6种策略都有一定的关联性。我们可以通过前缀将它们分为2类,volatile-与allkeys-,这两类策略的区别在于二者选择要清除的键时的字典不同,volatile-前缀的策略代表从设置了过期时间的key中选择键进行清除;allkeys-开头的策略代表从所有key中选择键进行清除。这里面值得介绍的就是lru与lfu了,下面会对这两种方式进行介绍。
1、LRU
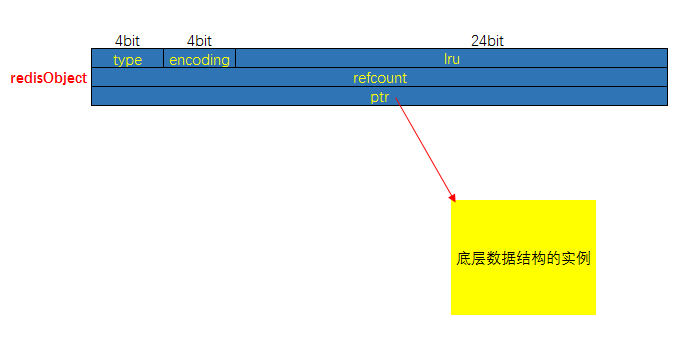
LRU是Least Recently Used的缩写,也就是表示最近很少使用,也可以理解成最久没有使用。也就是说当内存不够的时候,每次添加一条数据,都需要抛弃一条最久时间没有使用的旧数据。(一个key上一次的访问时间存储redisObject中的lru字段中,该点前文中有介绍《Redis:数据对象与底层实现》)
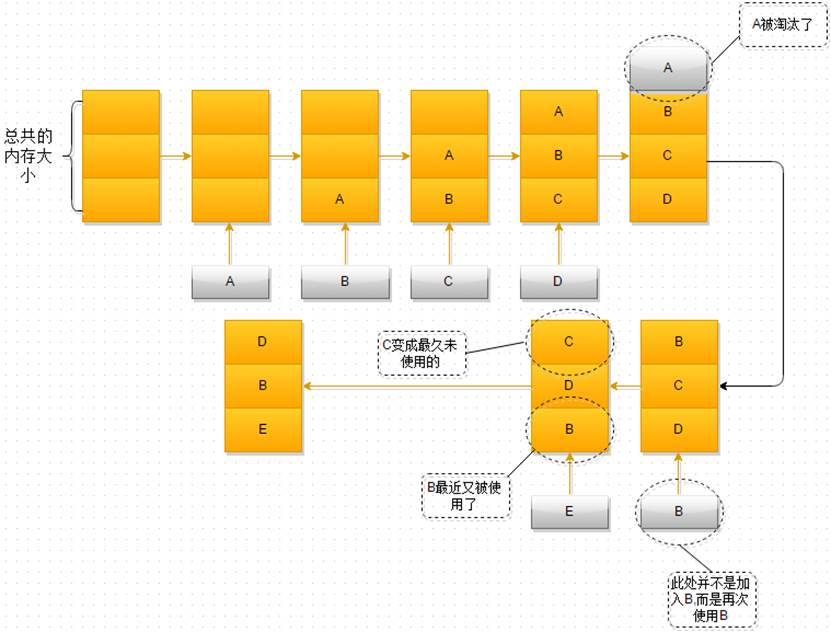
LRU 是基于链表结构实现的,链表中的元素按照操作顺序从前往后排列,最新操作的键会被移动到表头,当需要进行内存淘汰时,只需要删除链表尾部的元素即可。LRU的具体实现可以看看LeetCode上的经典题目146. LRU 缓存
需要注意的是Redis并没有使用标准的LRU实现方法作为LRU淘汰策略的实现方式,这是因为:
- 要实现LRU,需要将所有数据维护一个链表,这就需额外内存空间来保存链表
- 每当有新数据插入或现有数据被再次访问,都要调整链表中节点的位置,尤其是频繁的操作将会造成巨大的开销(不要忘了Redis就是为了存储热点数据而出现的,这必然导致数据出现高频的访问)
为了解决这一问题,Redis使用了近似的LRU策略进行了优化,平衡了时间与空间的效率。具体的实现细节我们会在下文中介绍。
LRU虽然看起来实现了按照数据的热度对内存中的key进行管理,但是在某些情况下却仍然存在一些问题,假设有一个数据很久没有被访问了,偶然间被访问了一次,lur字段值被更新,那么在lru的策略下,这个近期刚被访问过的节点会被保留,但显然这个key并不是我们想要保留的热点数据。为了解决这一问题,便有了LFU。
2、LFU
LFU(Least Frequently Used),表示最近最少使用,它和key的使用次数有关,其思想是:根据key最近被访问的频率进行淘汰,比较少访问的key优先淘汰,反之则保留。
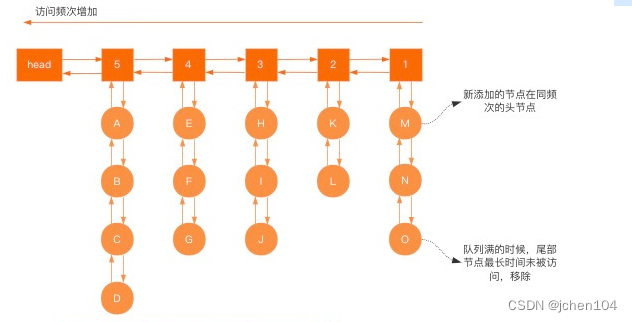
相比LRU算法,LFU增加了访问频率的这样一个维度来统计数据的热点情况,LFU主要使用了两个双向链表去形成一个二维的双向链表,一个用来保存访问频率,另一个用来访问频率相同的所有元素,其内部按照访问时间排序。
- 当添加元素的时候访问频次默认为1,于是找到相同频次的节点,然后添加到相同频率节点对应的双向链表的头部,
- 当元素被访问的时候就会增加对应key的访问频率,并且把访问的节点移动到下一个频次的节点。
LFU算法通过使用频率和上次访问时间来标记数据的这样一个热度,如果某个数据有读和写那么就增加访问的频率,如果一段时间内这个数据没有读写,那么就减少访问频率。所以通过LFU算法改进之后,就可以真正达到非热点数据的淘汰,当然LFU也有缺点,相比LRU算法,LFU增加了访问频次的一个维护,以及实现的复杂度比LRU更高。
1、内容简介
近似LRU在执行时,会随机抽取N个key,找出其中最久未被访问的key(通过redisObject中的lru字段计算得出),然后删除这个key。然后再判当前内存是超过限制,如仍超标则继续上述过程。
随机抽取的个数N可以通过redis.conf的配置进行修改,默认为5。之所以设置为5,是Redis官方压测后得出的结论(传送门)。
# The default of 5 produces good enough results. 10 Approximates very closely # true LRU but costs more CPU. 3 is faster but not very accurate. # # maxmemory-samples 5下图就是Redis官方的简述,大概意思为,当抽取参数为5时,已经很接近标准的LRU算法的效果了,虽然抽取参数为10时可以更接近,但是这会导致CPU的负担加重,折中考虑后选择了5。


另外,Redis3.0在2.8的基础上增加了一个淘汰池。在原来的策略中,每次抽取的key在删除最久未被访问的元素后即全部释放,而3.0增加了一个淘汰池(实现方式为数组),每次抽取完,都会将所有的key放入淘汰池中,然后删除数组最后一个非空元素(数组内按空闲时间由小到大排序,最后一个非空元素就是我们要删除的最久未被访问的元素),淘汰池种剩下的元素再参与下一次删除过程。
2、基础属性
在介绍近似LRU方法的源码前,我们先介绍2个下文要用到的基础属性
(1)redisDb
redis默认提供16个数据库,其中使用dict与expires两个字典结构分别报错该数据库内所有的key以及设置了过期时间的key。当我们的淘汰策略是volatile-lru时,则时从expires中取样。
// Redis 数据库。 有多个数据库由从 0(默认数据库)到最大配置数据库的整数标识。 // 数据库编号是结构中的“id”字段。 typedef struct redisDb { // 所有键值对 dict *dict; // 设置超时时间的key集合 dict *expires; // 数据库编号 int id; // 其他属性 ... } redisDb;(2)evictionPoolEntry
上文中提到了3.0时启用了淘汰池的策略,这个淘汰池默认大小为16,里面存放的元素为evictionPoolEntry类型。该类型中使用idle来记录每个key的空闲时间,当压入淘汰池中时就是通过比较该节点判断出所插入的位置。
// 淘汰池大小 #define EVPOOL_SIZE 16 // 淘汰池缓存的最大sds大小 #define EVPOOL_CACHED_SDS_SIZE 255 struct evictionPoolEntry { // 对象空闲时间,根据lru时间计算得到 unsigned long long idle; sds key; // 用来存储一个sds对象留待复用,注意我们要复用的是sds的内存空间 // 只需关注cached的长度(决定是否可以复用),无需关注他的内容 sds cached; // 数据库id int dbid; };3、源码详解
整个近似LRU的流程如下(图片来源《Redis的LRU缓存淘汰算法实现》):
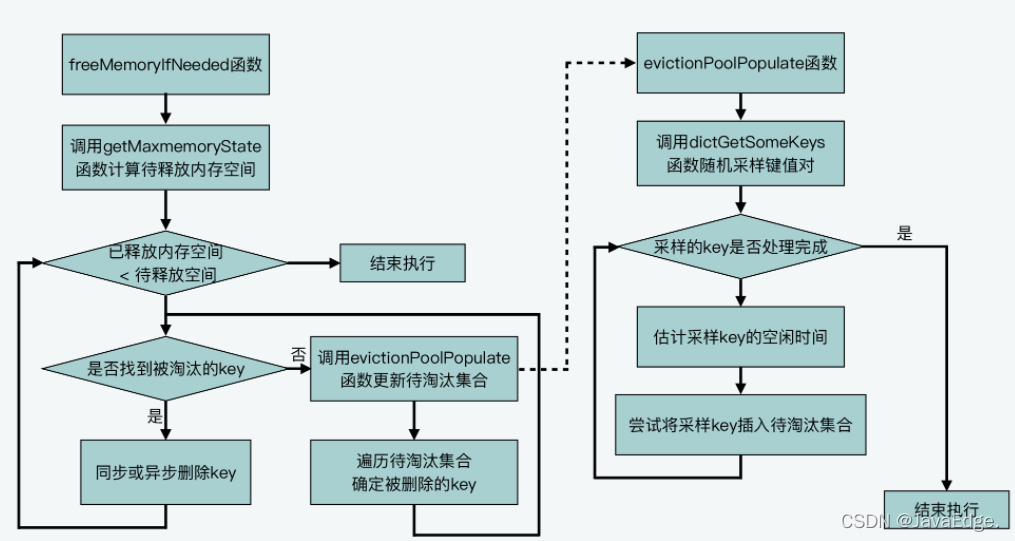
(1)整体流程
redis使用freeMemoryIfNeeded释放内存,该方法内部只要执行以下两个逻辑:
- 判断是否需要释放内存
- 循环释放内存直到满足要求
int freeMemoryIfNeeded(void) { // 三个变量分别为已使用内存、需要释放的内存、已释放内存 size_t mem_reported, mem_tofree, mem_freed; // 检查内存状态,有没有超出限制,如果有,会计算需要释放的内存和已使用内存 // 这个方法不但会计算内存,还会赋值 mem_reported mem_freed if (getMaxmemoryState(&mem_reported,NULL,&mem_tofree,NULL) == C_OK) return C_OK; // 初始化已释放内存的字节数为 0 mem_freed = 0; // 不进行内存淘汰 if (server.maxmemory_policy == MAXMEMORY_NO_EVICTION) goto cant_free; // 根据 maxmemory 策略遍历字典,释放内存并记录被释放内存的字节数 while (mem_freed < mem_tofree) { // 最佳淘汰key sds bestkey = NULL; // LRU策略或者LFU策略或者VOLATILE_TTL策略 if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) || server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { // 不同的策略找bestKey } /* volatile-random and allkeys-random policy */ else if (server.maxmemory_policy == MAXMEMORY_ALLKEYS_RANDOM || server.maxmemory_policy == MAXMEMORY_VOLATILE_RANDOM) { // 不同的策略找bestKey } // 最后选定的要删除的key if (bestkey) { // 在这里删除key } } }(2)抽取与删除
当策略为LUR时,会进行2个步骤
// LRU策略或者LFU策略或者VOLATILE_TTL策略 if (server.maxmemory_policy & (MAXMEMORY_FLAG_LRU|MAXMEMORY_FLAG_LFU) || server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { // 抽取key填充淘汰池 // 从淘汰池中删除末端的key }- 抽取key填充淘汰池
首先创建淘汰池,即一个大小为16的数组,然后遍历所有的数据库,进行取样抽取要删除的key,并调用evictionPoolPopulate将被抽取的key填充进入淘汰池。
// 淘汰池 struct evictionPoolEntry *pool = EvictionPoolLRU; while(bestkey == NULL) { unsigned long total_keys = 0, keys; // 从每个数据库抽样key填充淘汰池 for (i = 0; i < server.dbnum; i++) { db = server.db+i; // db->dict: 数据库所有key集合 // db->expires: 数据中设置过期时间的key集合 // 判断淘汰策略是否是针对所有键的 dict = (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) ? db->dict : db->expires; // 计算字典元素数量,不为0才可以挑选key if ((keys = dictSize(dict)) != 0) { // 填充淘汰池,四个参数分别为 dbid,候选集合,主字典集合,淘汰池 // 填充完的淘汰池内部是有序的,按空闲时间升序 evictionPoolPopulate(i, dict, db->dict, pool); // 已遍历检测过的key数量 total_keys += keys; } } // 如果 total_keys = 0,没有要淘汰的key(redis没有key或者没有设置过期时间的key),break if (!total_keys) break; /* No keys to evict. */- 从淘汰池中删除末端的key
在淘汰池中,所有节点按空闲时间由小到大的顺序排序(key插入其中的方法是从索引0位开始遍历找到第一个可插入位置),所以当要从其中删除最久未使用的元素时,逆序遍历数组找到的第一个非空元素即是我们的目标,找到这个元素后执行相应删除逻辑即可。
// 遍历淘汰池,从淘汰池末尾(空闲时间最长)开始向前迭代 for (k = EVPOOL_SIZE-1; k >= 0; k--) { if (pool[k].key == NULL) continue; // 获取当前key所属的dbid bestdbid = pool[k].dbid; if (server.maxmemory_policy & MAXMEMORY_FLAG_ALLKEYS) { // 如果淘汰策略针对所有key,从 redisDb.dict 中取数据,redisDb.dict 指向所有的键值集合 de = dictFind(server.db[pool[k].dbid].dict, pool[k].key); } else { // 如果淘汰策略不是针对所有key,从 redisDb.expires 中取数据,redisDb.expires 指向已过期键值集合 de = dictFind(server.db[pool[k].dbid].expires, pool[k].key); } if (pool[k].key != pool[k].cached) sdsfree(pool[k].key); // 从池中删除这个key,不管这个key还在不在 pool[k].key = NULL; pool[k].idle = 0; // 如果这个节点存在,就跳出这个循环,否则尝试下一个元素。 // 这个节点可能已经不存在了,比如到了过期时间被删除了 if (de) { // de是key所在哈希表节点,bestkey是 key 名 bestkey = dictGetKey(de); break; } else { /* Ghost... Iterate again. */ } } }(3)淘汰池的数据填充
在上文中,我们介绍到evictionPoolPopulate方法会将元素插入到淘汰池中,这里我们详细看下插入的方法。
整个过程也分为两部分是,插入位置查找与插入。
void evictionPoolPopulate(int dbid, dict *sampledict, dict *keydict, struct evictionPoolEntry *pool) { // 插入位置查找 // 复用插入位置的内存进行插入 }- 插入位置查找
这段逻辑首先计算空闲时间,针对不同的策略计算方法也各不相同。然后就是插入淘汰池,这里存在多个判断,分别如下:
(1)当前位置元素空闲时间小于key的空闲时间,则继续向后遍历
(2)key遍历到了某个位置,该位置左侧所有元素空闲时间均小于key,且该位置为空,则直接插入。由于整个查投入过程是从左到右的,所以当前key必然是目前最久未使用的key。
(3)key遍历到了某个位置,该位置左侧所有元素空闲时间均小于key,但此时该位置已有元素,不过数组最右侧为空,那么我们就将从这个位置到最右侧的所有元素全部右移一位,这样key就可以插入到当前位置了。
(4)key遍历到了某个位置,该位置左侧所有元素空闲时间均小于key,但此时该位置已有元素,同时整个数组都满了,因为我们要保留最久未使用的元素,所以这里我们与上文相反,将0到当前位置的元素全部左移一位,给key腾出插入空间。
// 初始化抽样集合,大小为 server.maxmemory_samples dictEntry *samples[server.maxmemory_samples]; // 此函数对字典进行采样以从随机位置返回一些键 count = dictGetSomeKeys(sampledict,samples,server.maxmemory_samples); for (j = 0; j < count; j++) { // 空闲时间 unsigned long long idle; // key sds key; // 值对象 robj *o; // 哈希表节点 dictEntry *de; de = samples[j]; key = dictGetKey(de); /* 如果我们采样的字典不是主字典(而是过期的字典),我们需要在键字典中再次查找键以获得值对象。*/ if (server.maxmemory_policy != MAXMEMORY_VOLATILE_TTL) { if (sampledict != keydict) de = dictFind(keydict, key); o = dictGetVal(de); } /* 根据策略计算空闲时间 */ if (server.maxmemory_policy & MAXMEMORY_FLAG_LRU) { // 给定一个对象,使用近似的 LRU 算法返回未请求过该对象的最小毫秒数 idle = estimateObjectIdleTime(o); } else if (server.maxmemory_policy & MAXMEMORY_FLAG_LFU) { // LFU 策略也是用这个池子 idle = 255-LFUDecrAndReturn(o); } else if (server.maxmemory_policy == MAXMEMORY_VOLATILE_TTL) { // 在这种情况下,越早过期越好。 idle = ULLONG_MAX - (long)dictGetVal(de); } else { serverPanic("Unknown eviction policy in evictionPoolPopulate()"); } /* 将元素插入池中*/ k = 0; // 遍历淘汰池,从左边开始,找到第一个空位置或者第一个空闲时间大于等于待选元素的位置,k是该元素的坐标 while (k < EVPOOL_SIZE && pool[k].key && pool[k].idle < idle) k++; if (k == 0 && pool[EVPOOL_SIZE-1].key != NULL) { /* 如果元素小于我们拥有的最差元素并且没有空桶,则无法插入。 * * key == 0 说明上面的while循环一次也没有进入 * 要么第一个元素就是空的,要么所有已有元素的空闲时间都大于等于待插入元素的空闲时间(待插入元素比已有所有元素都优质) * 又因为数组最后一个key不为空,因为是从左边开始插入的,所以排除了第一个元素是空的 */ continue; } else if (k < EVPOOL_SIZE && pool[k].key == NULL) { /* 当前位置无元素,直接插入即可 */ } else { // 当前key找到了数组中可插入的位置,但该点已有元素时存在2种可能 if (pool[EVPOOL_SIZE-1].key == NULL) { // 1.数组未满,最右侧为空,则当前位置向右的所有元素全部 // 右移一位,以此来实现元素的插入 /* 覆盖前保存 SDS */ sds cached = pool[EVPOOL_SIZE-1].cached; // 注意这里不设置 pool[k], 只是给 pool[k] 腾位置 memmove(pool+k+1,pool+k, sizeof(pool[0])*(EVPOOL_SIZE-k-1)); // 转移 cached (sds对象) pool[k].cached = cached; } else { // 2. 数组已满,则将0到当前位置(k)的元素由1到k的元素覆盖 // 并将key插入到k的位置 k--; sds cached = pool[0].cached; if (pool[0].key != pool[0].cached) sdsfree(pool[0].key); memmove(pool,pool+1,sizeof(pool[0])*k); pool[k].cached = cached; } }总结一下就是:
无论何时,空闲时间小于最小元素的不能插入
淘汰池未满时,空闲时间大于最大元素,则插入到右侧第一个空位;空闲时间介于最小与最大之间,则将大于key空闲时间的元素全部右移一位,然后插入key。
淘汰池满了后,则将小于key空闲时间的元素全部左移一位(这里会抛弃第0位的元素),然后插入key。
- 插入key
/* * 尝试重用在池条目中分配的缓存 SDS 字符串,因为分配和释放此对象的成本很高 * 注意真正要复用的sds内存空间,避免重新申请内存,而不是他的值 */ int klen = sdslen(key); // 判断字符串长度来决定是否复用sds if (klen > EVPOOL_CACHED_SDS_SIZE) { // 复制一个新的 sds 字符串并赋值 pool[k].key = sdsdup(key); } else { /* * 内存拷贝函数,从数据源拷贝num个字节的数据到目标数组 * * destination:指向目标数组的指针 * source:指向数据源的指针 * num:要拷贝的字节数 * */ // 复用sds对象 memcpy(pool[k].cached,key,klen+1); // 重新设置sds长度 sdssetlen(pool[k].cached,klen); // 真正设置key pool[k].key = pool[k].cached; } // 设置空闲时间 pool[k].idle = idle; // 设置key所在db pool[k].dbid = dbid; }至此,近似LRU查找要删除的key的过程就介绍完毕了,后面就是删除的过程了,这里不多作介绍了,有兴趣的可以看看这篇文章,有详细介绍《Redis 内存淘汰策略》。
1、淘汰策略的选择
- 如果数据呈现幂等分布(即部分数据访问频率较高而其余部分访问频率较低),建议使用 allkeys-lru。
- 如果数据呈现平等分布(即所有数据访问概率大致相等),建议使用 allkeys-random。
- 如果需要通过设置不同的ttls来确定数据过期的顺序,建议使用volatile-ttl。
- 如果你想让一些数据长期保存,而一些数据可以消除,建议使用volatile-lru或volatile-random。
由于设置expire会消耗额外的内存,如果你打算避免Redis内存浪费在这一项上,可以选择allkeys-lru策略,这样就可以不再设置过期时间,高效利用内存。
2、使用建议
虽然Redis提供了内存淘汰策略,但我们最好还是精简对Redis的使用,尽量不要淘汰内存数据。下面是一些使用建议:
- 不要放垃圾数据,及时清理无用数据。
- key尽量都设置过期时间。对具有时效性的key设置过期时间,通过redis自身的过期key清理策略来降低过期key对于内存的占用,同时也能够减少业务的麻烦,不需要定期手动清理了。
- 单Key不要过大,这种key造成的网络传输延迟会比较大,需要分配的输出缓冲区也比较大,在定期清理的时候也容易造成比较高的延迟. 最好能通过业务拆分,数据压缩等方式避免这种过大的key的产生。
- 不同业务如果公用一个业务的话,最好使用不同的逻辑db分开。这是因为Redis的过期Key清理策略和强制淘汰策略都会遍历各个db。将key分布在不同的db有助于过期Key的及时清理。另外不同业务使用不同db也有助于问题排查和无用数据的及时下线。
3、修改方式
- 方式一:通过 config set maxmemory-policy 策略 命令设置。它的优点是设置之后立即生效,不需要重启 Redis 服务,缺点是重启 Redis 之后,设置就会失效。
- 方式二:通过修改 Redis 配置文件修改,设置 maxmemory-policy 策略,它的优点是重启 Redis 服务后配置不会丢失,缺点是必须重启 Redis 服务,设置才能生效
热门文章
- 宠物粮食供应商真的赚钱吗知乎(宠物粮食利润大吗)
- 无货源网店赚钱吗?(无货源网店赚钱吗)
- 2022公务员国考报考条件及时间(2022公务员国考报考条件及时间表)
- 4月5日→18.1M/S|2025年最新免费节点Free V2ray订阅链接地址分享
- kafka开机自启动配置
- 220v小型饲料颗粒机多少钱一台(小型颗粒饲料机多少钱一台最便宜)
- 3月24日→19.6M/S|2025年最新免费节点Free V2ray订阅链接地址分享
- 长沙宠物领养中心官网电话 长沙宠物领养中心官网电话号码
- 3月7日→18.8M/S|2025年最新免费节点Free V2ray订阅链接地址分享
- 软件的23种设计模式的通俗解释